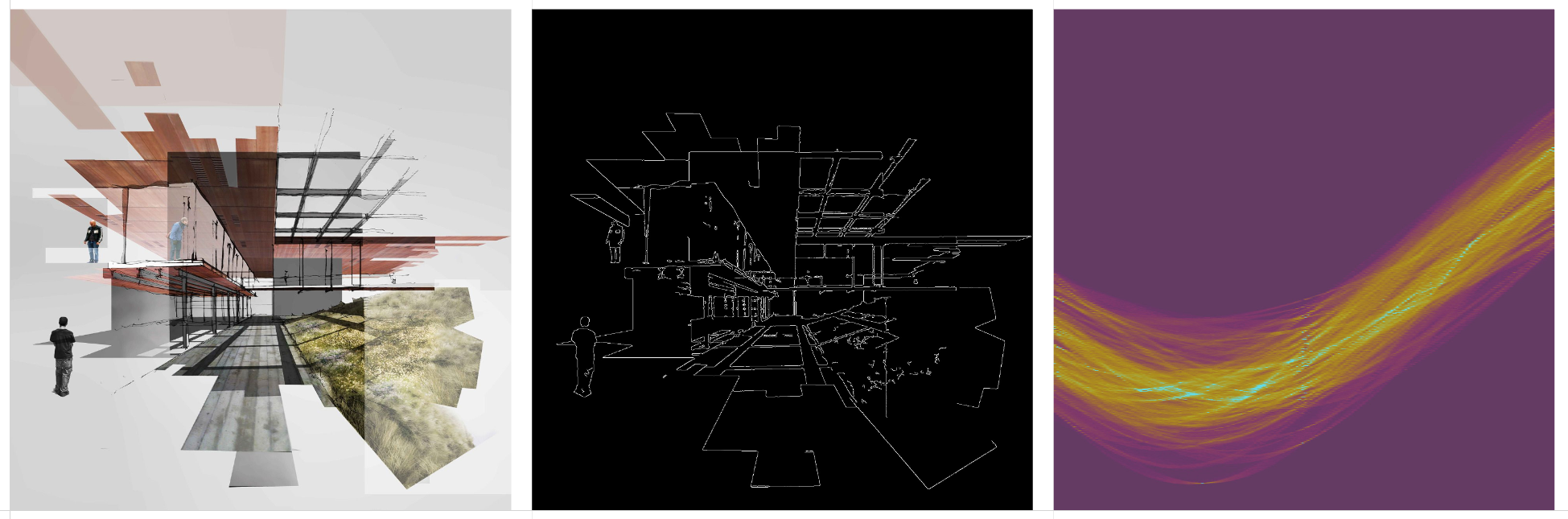
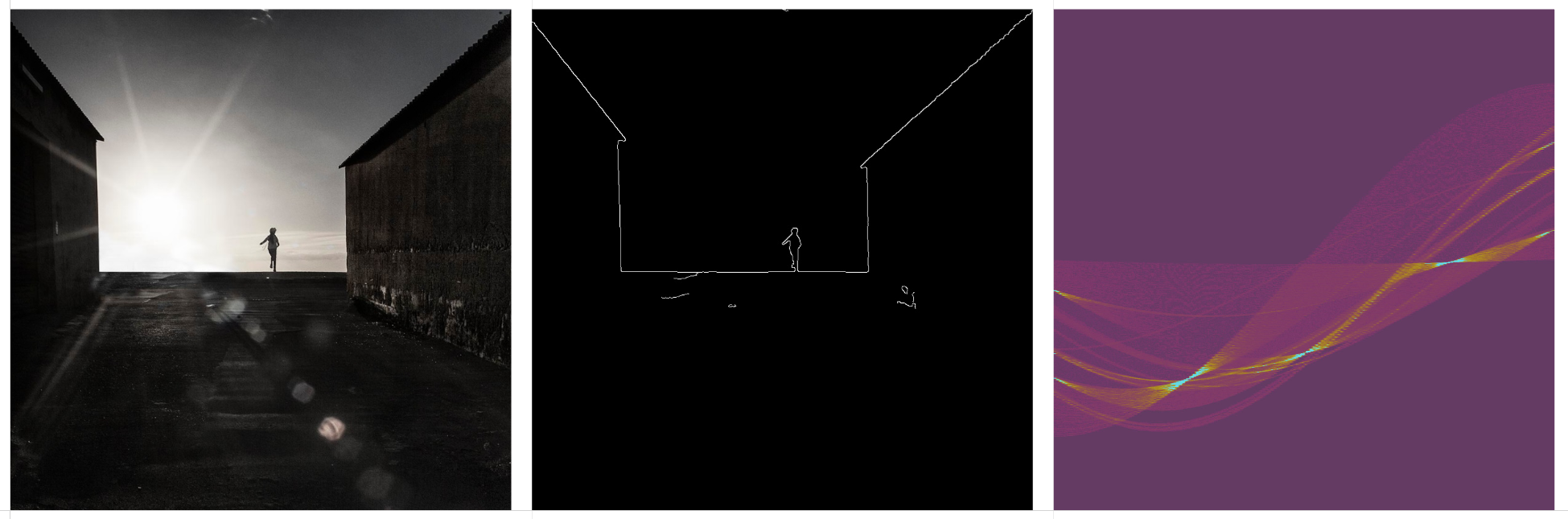
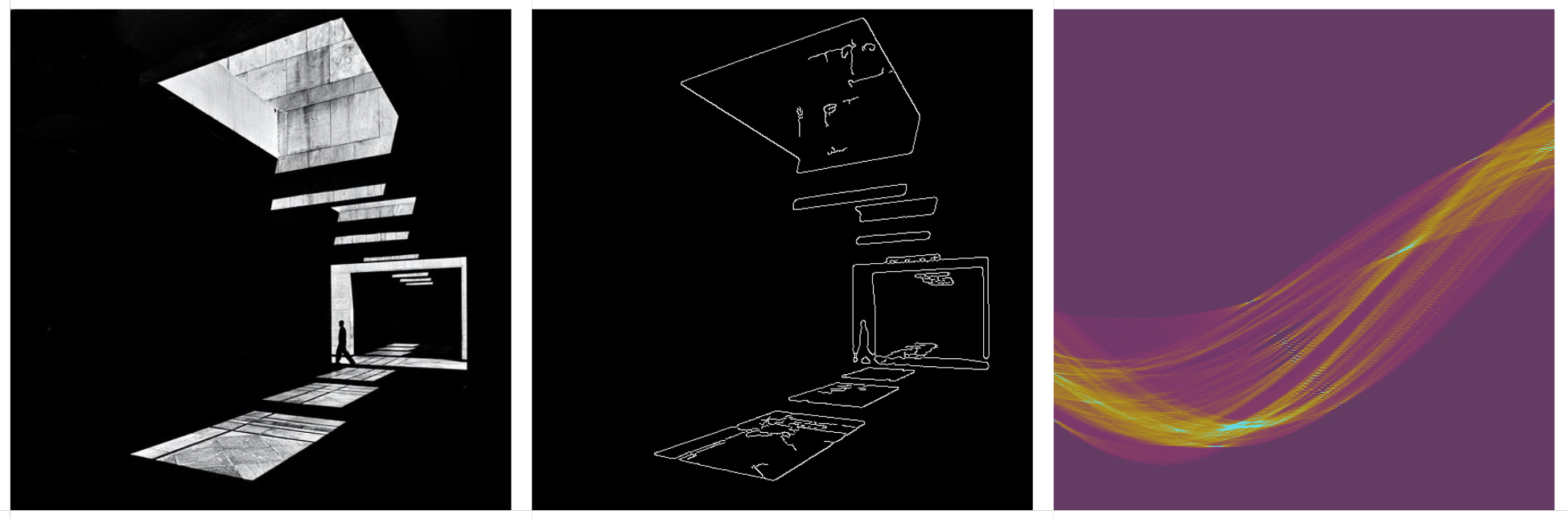
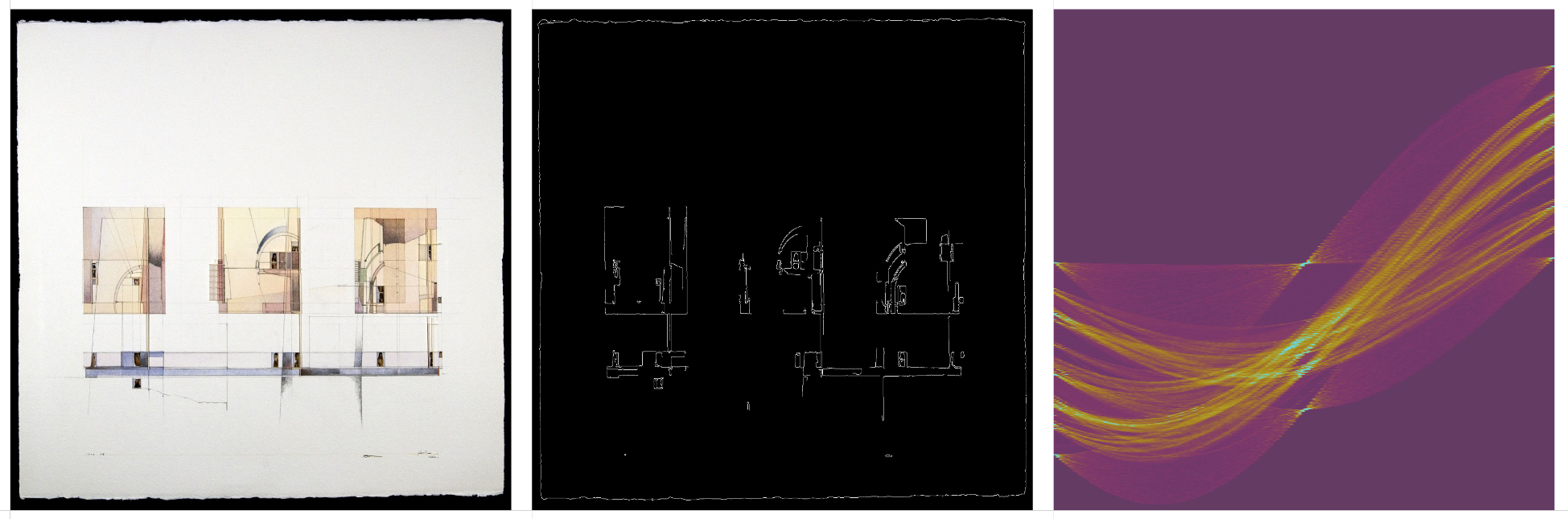
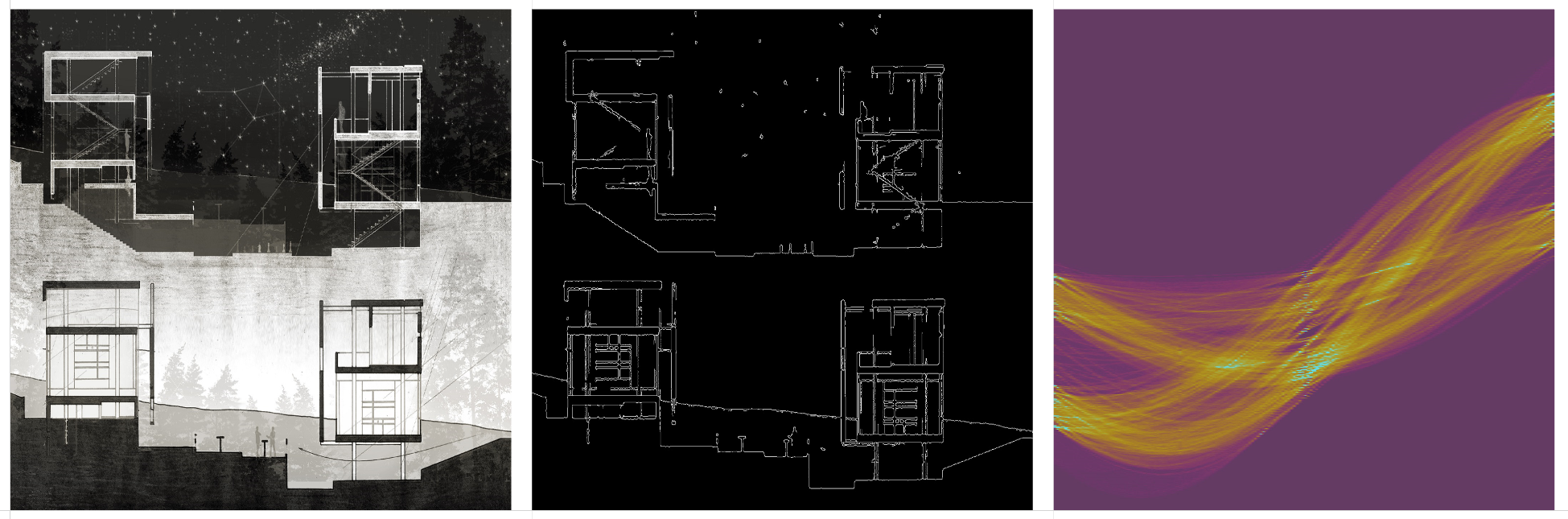
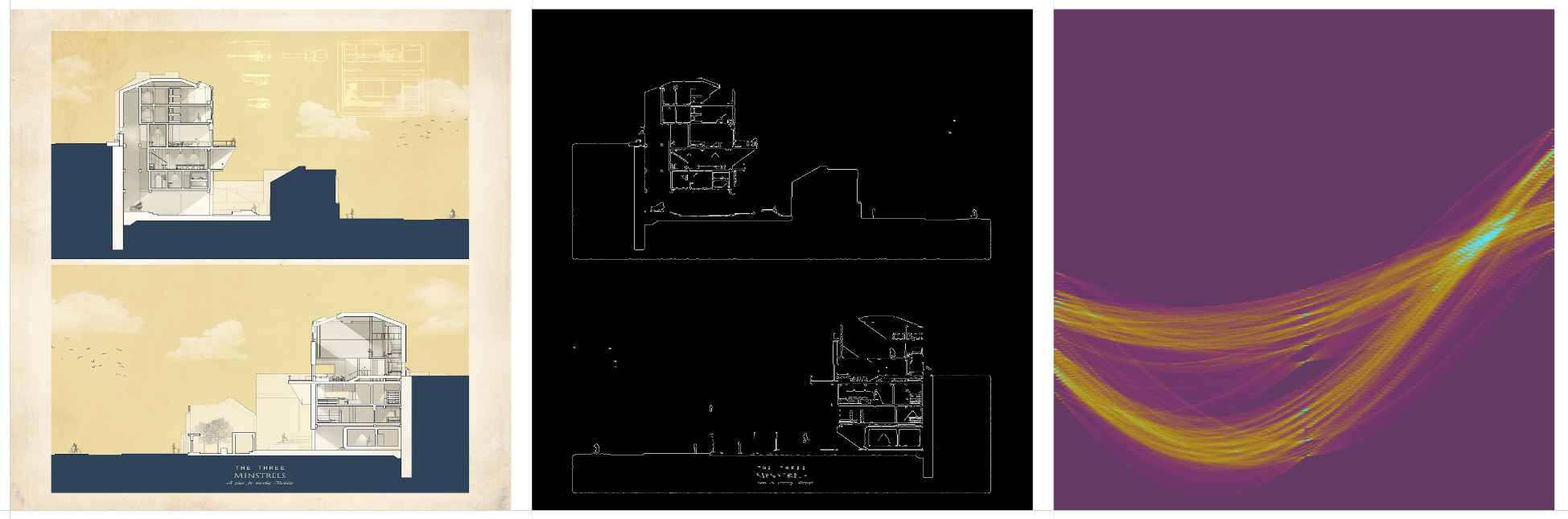
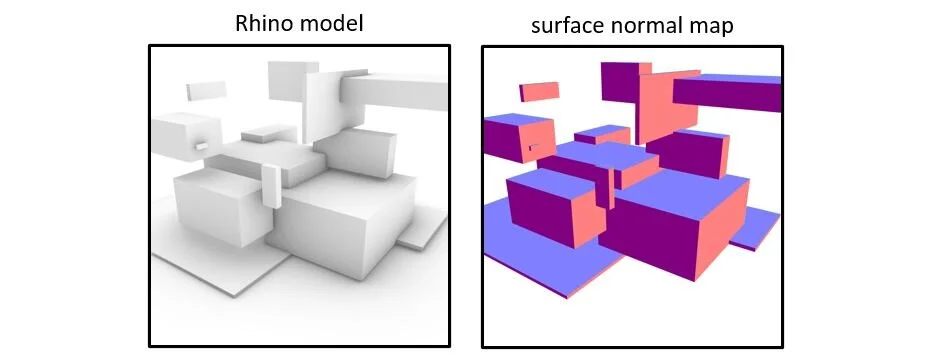
Some thoughts on the question of authorship when using generative AI tools.
TLDR: I think it’s most prudent to provide a short list of collaborators, rather than a sole author. For example, list the relevant Primary Author / Product / Model / Training Data.

ie: Adam Heisserer/ StyleGAN2 / GAN
Who wrote the song ‘Yesterday’? One morning, Paul McCartney woke up with the tune in his head. It sounded so familiar, he assumed he was remembering a pre-existing tune. After a while, he accepted that it was not a pre-existing song, but a novel one that appeared to him. So who wrote it? Was it Paul McCartney, who spent a lifetime crafting and listening to music? This is the equivalent of training data and the latent space that makes up all the potential songs that could be, based on what he knows about the structure and characteristics of all songs. Was it Paul’s sleeping subconscious brain that wrote it? In part, yes. Or was it waking Paul, who had the wherewithal to recognize, remember and record the tune after consciously authoring the lyrics? I’d say it was all three. Because there’s not much of a legal distinction between Paul and his subconscious sleeping brain, it’s practical to just to name him the sole author.
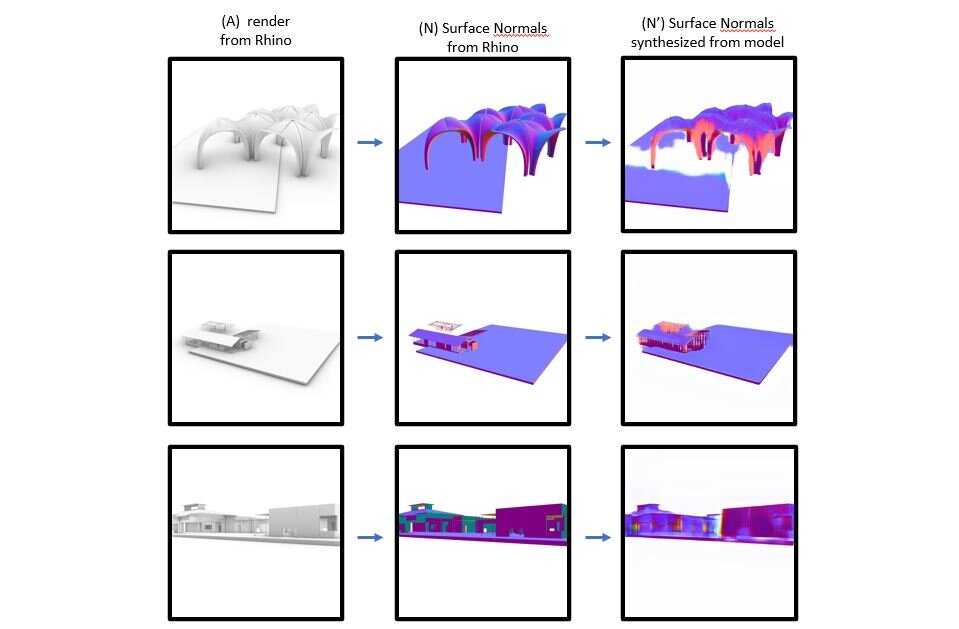
When using generative AI tools to create images, there is a distinction between the human curator and the model ‘dreamer’. More of a co-authorship that’s worth acknowledging. Further distinction could be made to include who authored, and who curated the training data. Or, who crafted the exact generative process.
If there’s a question of authorship, list multiple co-authors. Don’t be dishonest, but don’t overthink it. Because of their generative nature and vast training data, this includes generative AI image models.